Die Edition ermöglicht, die digitale Form der originalen Handschrift mit der
wissenschaftlichen textkritischen und kommentierten Edition des Textes und mit
nötigen beschreibenden Metadaten an einem Ort zugänglich zu machen. Die digitale
Edition der LA wird im internationalen Standard XML TEI verarbeitet. Dieser hält die
genaue strukturelle, formale und inhaltliche Seite der Quelle einschließlich der
Evidenz und Verwaltung der Versionen der einzelnen Handschriften fest und kann
zugleich auch die Edition effektiv um zusätzliche Informationen zur Interpretation
aus einer spezialisierten Datenbasis oder weiterer Quellen ergänzen, ohne dass nötig
wäre, in den urprünglichen Text einzugreifen. Der Prozess der Vorbereitung der
Edition und der Vorgang des Ausfüllens der Datenbasis sind dabei also zweibahnig
verknüpft. Bei der Vorbereitung der Edition werden die Einträge in der Datenbasis
gebildet oder ergänzt und die später aus anderen Quellen ergänzten Informationen
werden in den Anmerkungsapparat rückwärts projiziert.
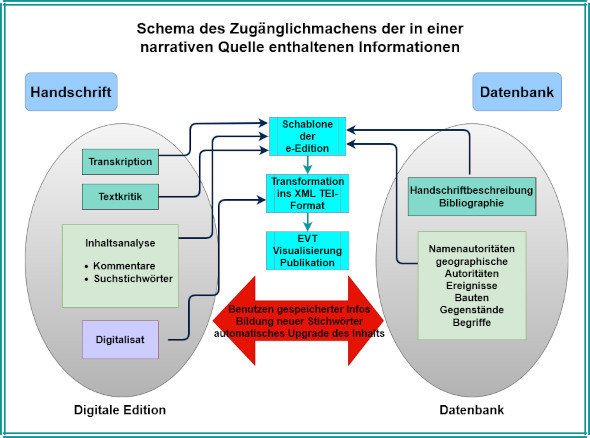
Bei der Arbeit mit Texten benutzen wir übliche Methoden für die Bildung der
Editionen ohne Rücksicht auf die Form ihres Zugänglichmachens. Am Anfang werden also
einzelne Handschriften aus der Sicht ihrer Qualität und Zugänglichkeit bewertet und
es wird die Haupthandschrift gewählt. Danach schreibt ein qualifizierter Abschreiber
den Text ab und nach der Erhältung der Handschriften wird die Kollation minimal mit
einer oder mit mehreren Handschriften durchgeführt. Für die eigene Editionsarbeit
definieren wir zwei Formen der Verarbeitung:
- Vollständige textkritische Edition
- macht den Text aufgrund der Kollation aller Handschriften zugänglich
- bildet den vollen textkritischen Apparat, der verschiedene Type der
Unterschiedlichkeiten der Handschriften reflektiert
- registriert die Erscheinungen (einschließlich der Autorenstriche), welche
zum Verständnis der Entstehung des Textes beitragen können
- Kommentierte Edition mit dem vereinfachten textkritischen Apparat
- macht den Text aufgrund der Kollation mit minimal einer der Nebenhandschriften
zugänglich
- reflektiert nicht Type der festgestellten Varianten
- reflektiert nicht ortographische Varianten (mit Ausnahme der Eigennamen und
Toponyme)
- registriert nicht Autorenstriche
- bildet Kommentäre für besseres Begreifen des Textes und Register zum Durchsuchen
Die erste Form der Edition halten wir nur in den Fällen für nutzbringend, falls die
Handschriften wesentlichere Unterschiede aufweisen oder falls ein Konzept der
Berichte mit Verbesserungen eines Verfassers oder Korrektors (vieleicht des Rektors
des Kollegs) erhalten blieb. Darum ist die kommentierte Edition mit dem
vereinfachten textkritischen Apparat die überwiegende Form für die
Edition der LA. Sie wird um Interpretationselemente und ums Durchschalten mit der
spezialisierten Datenbasis bereichert, was weitere Forschungsarbeit erleichtert. Die Regeln für die Transkription und
Edition der Texte der LA gehen von bisherigen Studien aus, die sich mit den
Editionen der frühneuzeitlichen Texte beschäftigen und zugleich spezifische Züge der
jesuitischen Schriftsstücke sowie Bedürfnisse der Benutzer der Edition reflektieren.
Auβer dem standarden textkritischen Apparat bildeten wir für diese digitale Edition
auch das verhältnismäßig umfangsreiche System der inhaltlichen Kommentare, welche im
TEI-Format zugleich als Grund der Register und weiterer Aussuchungsmöglichkeiten
dienen. Jeder Kommentar wird mit dem entsprechenden Eintrag verbunden, aus dem das
zugehörige Registerstichwort automatisch generiert wird. Die Visualisierungssoftware
dann ermöglicht dem Forscher den direkten Zutritt nicht nur zu den textkritischen
Anmerkungen, sondern auch zu den weiteren zusätzlichen Registerinformationen direkt
aus der Edition. Bei der Interpretation der Texte orientieren wir unsere
Aufmerksamkeit vor allem auf
- Personen.
Es geht sowohl um die Personen, deren Namen sich direkt im Text befinden, als
auch um die Personen, die aufgrund ihrer Funktionen oder Rollen in gegeben Zeit
oder und am gegebenen Ort identifiziert wurden. Z. B. falls die Berichte einen
Vertreter der Kirche oder des Jesuitenordens anführen, ordnen wir die allgemeine
Bezeichnungen („decanus Telczensis“, „decanus Slavonicensis“, „praepositus
Neoreschensis“) zu den konkreten Personen zu, die diese Ämter im gegebenen Jahr
bekleideten. Falls der Text die Aktivitäten der Fundatorin oder der Obrigkeit
erwähnt, dann suchen wir zu den allgemeinen Bezeichnungen „fundatrix nostra“
oder „illustrissimus hujatus dominus“ die konkreten Namen der Angehörigen des
regierendes Geschlechts aus.
- Korporationen.
Es geht um Institutionen, Korporationen und spezifische Organisationen (z.B.
Studentenstiftungen), die im Text direkt angeführt oder mit vertretenden
Begriffen bezeichnet sind, bzw. mit dem Text unmittelbar zusammenhängen. Z.B.
das von Franziska von Slavata gegründete musikalische Seminarium wird in der
Quelle als „seminarium musorgorum“, „convictus musorgorum“, „convictus
Angelicus“ oder nur einfach als „seminarium nostrum“ oder „convicus nostrus“
bezeichnet.
- Ortschaften (Geographische Termini).
Die Lokalität wird identifiziert, einschlieβlich der Angabe der GPS-Koordinaten, die ihre Abbildung an der Landkarte ermöglichen.
- Ereignisse.
Es geht z.B. um religiöse Festlichkeiten (feierliche Messen, Prozessionen),
Theatervorstellungen sowie auch um Bautätigkeit (Speicherbau, Teichbau),
Reparaturen der Immobilien (Dachrekonstruktion, Malen der Objekte, Pflanzung der
Wälder und Gärten), Einkäufe und Verkäufe der Güter, Abschliessen der Verträge,
Lösen der Streite, Erwerben und Reparaturen der Mobilien (Bücher, Möbel,
liturgische Gegenstände, Kleidung, Kunstsammlungen). Im Fall, dass es um eine
Aktion geht, die mit den mobilen oder immobilen Gegenständen zusammenhängt,
weisen wir an den entsprechenden Gegenstand oder Bau hin.
- Bauten.
Für Bauten halten wir alle immobilen Denkmäler, einschließlich der kleinen
sakralen Architektur, Wirtschaftsbauten und ihrer Bestandteile, die allmählich
und im Rahmen eines größeren Baukomplexes entstanden. Wir registrieren sie als
Schauplätze der Aktionen, Sitze der Korporationen, Objekte der Bautätigkeit oder
als Opfer der Katastrophen. In die Kategorie „Bauten“ reihen wir auch Elemente
der Kulturlandschaft und verschiedene Type des bearbeiteten Bodens (Gärten,
Felder, Obstgärten) ein. Angesichts der Tatsache, dass viele Bauten auch als
„Schauplatz/Ort eines Geschehens“ erwähnt werden, klasifizieren wir sie auch als
spezifischen Typ der Lokalität.
- Gegenstände.
Als „Gegenstand“ bezeichnen wir alle mobilen Sachen, wie z.B. liturgische
Gegenstände, Bekleidung, Möbel und Kirchenmobiliar. In diese Gruppe gehören auch
Bücher, wenn auch ihre Evidenz selbständigen Regeln unterliegt. Die meisten
erwähnten Bücher sind nämlich mit einem konkreten erhaltenen Exemplar nicht zu
identifizieren. Darum gehen wir mit ihnen ähnlich wie mit anderen Gegenständen
um und im Fall der identifizierten Bücher arbeiten wir mit standarden
Katalogisierungseinträgen.
- Begriffe.
Wir evidieren alle in den Texten vorkommenden Termini. Unser Ziel ist, so einen
Register zu schaffen, der das Suchen mit Hilfe sowohl der Begriffe in der
Sprache des Originaltextes als auch ihrer tschechischen Equivalenten ermöglicht.
Gewöhnlich geht es um die Bezeichnungen der Funktionen, Gegenstände,
Aktivitäten, Kirchenfeste oder weiterer Tatsächlichkeiten, welche in den Texten
in vielen synonymen Bezeichnungen vorkommen, die wir in einen üblichsten Begriff
zusammenfassen (z.B. unter dem Terminus „concionator“ befinden sich die
synonymen Ausdrücke „encomiastes“, „pangeyrista“, „sacer orator“ usw.) und
diesen wir mit der entsprechenden Bedeutungserklärung ergänzen.
Das XML TEI-Format wird im akademischen Milieu vor allem für die Verarbeitung der
elektronischen Texte und digitalen Dokumente aus dem Bereich der Humanwissenschaften
allgemein angenommen. Sein Grund bildet die universale Zeichensprache XML
(eXtensible Markup Language). Das TEI-Format bilden und verwalten Fachleute, die
sich in der Assoziation Text Encoding Initiative gruppierten. Die Struktur des
TEI-Formats (letzte Version P5), definiert in TEI Guidelines, orientiert sich auf
die Beschreibung der Inhaltsstruktur eines Dokuments und seiner Metadaten. Sie
enthält eine komplexe Gesamtheit der Elemente (Zeichen) und entsprechenden
Attributen (Eigenschaften) für das Kodieren des breiten Spektrums der Texte, die
unterschiedlichen Charakter, verschiedene Zeiteinreihung und formale Anordnung
(Prosa, Poesie, Drama, Lexika, Handschriften, alte Drucke) aufweisen. Das finale
XML-Dokument kann mittels der Kaskadenstilen Cascading Style Sheets) und
Transformationen (z.B. mittels XSLT4) an verschiedene Endformate (Web, gedrucktes
Medium, Pdf, epub) angepasst werden.
Was das Kodieren der elektronischen Edition der LA betrifft, benutzen wir außer den
allgemeinen Zeichen für popis metadatdie Beschreibung der Metadaten (<teiheader>) und der
formalen Textstruktur (Absätz, Anmerkungen, bibliographische Zitationen, Referenzen) sowie v.a. Teile der TEI-Definitionen, welche für die Arbeit mit
handschriftlichen Texten und für die Repräsentation der Primarquellen bestimmt
sind. Für die Verbindung der Transkription mit einem Faksimile benutzen wir die
Methode der paralellen Transkription (Parallel Transcription).5 Das
Verweisungssystem des kritischen Apparats wird mit der paralellen
Segmentationsmethode (Parallel Segmentation Method) mit der Preferenz des
positiven Apparats, d.h. für alle Posten des kritischen Apparats <app> führen wir
die Elemente <lem> und <rdg> an. Für den Charakter des Projekts und die Arbeit
mit den Kommentaren sind auch die Elemente wichtig, welche die
Inhaltselemente (sog. Named Entities) bezeichnen. Neben der Grundelemente
<name>, <date>, <place> beutzen wir im Projekt auch die Zeichen für die
Bezeichnung der Korporationen (<orgname>), Ereignisse (<event>),
Gegenstände (<objectname>) und Begriffe (<term>). Entsprechende
Registerverzeichnisse werden mit Hilfe der Elemente <list>
(z.B. <listperson>, <listorg>;) gebildet.
Für jedes Jahr der Existenz der LA wird eine selbstständige XML-Datei gebildet, die auch das Kodieren der Variantenhandschriften mit Hilfe des Elements
<listWit> und des Verweisungsattributs @wit enthält.
Beispiele des Kodierens für die Pilotjahre der Edition LA 1702 (vollständige textkritische
Edition) und LA 1729
(kommentierte Edition mit dem vereinfachten textkritischen Apparat) sowie die
ausführliche Übersicht der Type
der Textvarianten, semantischen Kommentare, Registerstichworte und ihrer Representation durch die TEI-Elemente stehen als
Beilagen der zertifizierten Methodik Nr. 3, 6, 8, 9, 10 zur Verfügung und können
herunterladen werden.
Weil das direkte Kodieren der Texte im XML-Editor halten die meisten Mitarbeiter
für schwierig, benutzen wir für editorische Arbeit das Instrument der E-Edition,
welches Mitarbeiter der Abteilung für die Sprachentwicklung des Instituts für die
tschechische Sprache entwickelten. Es ist in der "Methodik für Vorbereitung und
Verarbeitung der elektronischen Editionen der älteren tschechischen Texte
beschrieben." Die E-Edition wird als Schablone (eEdice.dotx) und die Ergänzung des
Texteditors MS Word installiert. Sie dient zur Bezeichnung der relevanten Teile des
Quellentextes und zum Bilden der textkritischen und inhaltlichen Kommentäre. Die in
der Schablone definierten Absatz- und Zeichenstile sind in weiteren Schritten
authomatisch auf die entsprechenden Elemente des Formats TEI P5. Die Schablone
enthält auch eine Einführungstabelle für die Einschreibung der Metadaten. Für unsere
Bedürfnisse wurde die ursprüngliche Version der Schablone für die Arbeit mit den
Varianten der Handschriften angepasst. Die Verbindung mit der Datenbank wurde
zusätzlich einprogrammiert und das ermöglicht, parallel mit der Verarbeitung des
Textes der Edition auch die Eintragungen in der Datenbank gegenseitig zu verbinden
und zu aktualisieren.
Nach dem Beenden sind die Word-Dokumente in Zusammenarbeit mit den Kollegen aus dem
Institut für tschechische Sprache durch ganze Reihe der XSLT-Transformationen auf
XML-Dateien gebracht, welche noch im Editor Oxygen1 final revidiert werden. Die
Übersicht der benutzten Stile und ihre Übertragung in TEI und Beispiele der
Editorarbeit in der Schablone E-Edition für die Pilotjahre 1702 (vollständige
textkritische Edition) und 1729 (kommentierte Edition mit dem vereinfachten
textkritischen Apparat) stehen als Beilagen Nr. 1,2,5 der zertifizierten Methodik
zur Verfügen und können herunterladen werden.
Als Datenbank für das Speichern der Daten, welche die E-Edition benutzt und die aus
den editierten Texten exzerpiert wurden, benutzen wir die Bio-bibliographische Datenbank der Ordensbrüder in den böhmischen
Ländern in der frühen Neuzeit. (BBDR). Die Datenbank entstand im Jahre 2010
und wurde als Raum zum Versammeln der Informationen über das Leben der religiösen
Gemeinschaften konzipiert. Sie wird auf dem modifizierten Bibliotheksystem Clavius gegründet, das
internationale Bibliothekstandarden MARC21 und UNIMARC respektiert. Zuerst
wurden biographische Informationen und ihre Quellen betont. Danach wurde die
Datenbank in zwei Hauptmodule entwickelt. Erstens ging es um die Datenbank der
Hauptauthoritäten (= Datenbank der Ordensbrüder des 17. und 18. Jahrhunderts aus den
böhmischen Ländern), die biografisch orientiert wurde. Zweitens handelte es sich um
den Katalog der Handschriften (= Datenbank der narrativen historischen Quellen der
Ordensprovenienz aus dem 17. und 18. Jahrhundert), der auf den bibliographischen
Angaben beruht. Zu weiteren bibliographischen Modulen gehören sowohl der Katalog der
alten Drucke als auch der Katalog der Bücher, welche jedoch nur unterstützende
Funktion haben.
Außer aller oben erwähnten Modulen benutzt die digitale Edition auch die Module der
geographischen Autoritäten und Korporationen. Neu wurde das Modul der sachlichen
Autoritäten angepasst, damit es möglich war, sowohl die mit dem Leben der
Jesuitischen Kommunität zusammenhängende Begriffe und Funktionen (einschließlich der
Evidenz der kirchlichen Feste), als auch die in den Jahresberichten erwähnten
Informationen über die Bauten und über das weitere mobile und immobile Vermögen in
der Datenbank zu evidieren. Alle Einträge in der Datenbank werden mit dem
ausarbeiteten Alias-System versehen. Das ermöglicht das bessere Aussuchen nicht nur
aufgrund der synonymischen lateinischen Bezeichnungen sondern auch aufgrund ihrer
tschechischen Übersetzungen und verschiedenster Varianten der Orts- und Eigennamen
(Alias). Zum Beispiel:
- Telč - Telcz - Teltsch
- Ignatius de Loyola - divus Patriarcha Noster Ignatius - Sanctus Patriarcha
Noster - Ínigo López de Loyola - Ignác z Loyoly
- Daemon - Diabolus - Ďábel - Malignus spiritus - Spiritus malignus
- seminarium musorgorum - seminář svatých andělů - hudební seminář - convictus musorgorum - convictus Angelicus
In den Fällen, in denen es die gültige Legislative ermöglicht, bilden den
Bestandteil unserer elektronischen Edition LA auch elektronische Kopien der
einzelnen erhaltenen Handschriften. Das benutzte Visualisierungssystem EVT
ermöglicht die Verbindung des Textes mit dem digitalen Bild des Originals entweder
an der Ebene der Seiten (mit Hilfe des Elements <pb>) oder der Zeilen ( <lb>). Die
gewonnene oder in den Erinnerungsinstitutionen angeschafften Digitalisate müssen
jedoch für die Zwecke der Webpublikation formal hergerichtet und vereinigt
werden. Für diese Zwecke benutzen wir das Open-source-Programm Scan Tailor, das
zur dávkovému? Verarbeitung der Bilddaten dient. Das Programm ermöglicht die
folgenden Operationen durchzuführen:
- Veränderung der Seitenorientierung (Drehen um 90, bzw. 180 Grad)
- Teilen der Folien auf einzelne Seiten (Doppelseite wird auf selbstständige Seiten geteilt)
- Detektion und Beschneiden der leeren Ränder um den Text herum
- Ausgleichen der Ränder mit Hilfe der kleinen Umdrehung des Bildes
- Einstellung der Ausgangsparameter der Bilder (Format, Größe, DPI-Auflösung)
Das erwählte Programm ist darum vorteilhaft, dass es die Veränderungen des Bildes
selbst feststellen und auf alle Dateien in der Komponente applizieren kann. Falls
eine Datei nicht standarde Elemente enthält, ist es möglich, einzelne Schritte
manuell durchzuführen.
Für das Publizieren der LA-Edition benutzen wir open source
Visualisierungsinstrument Edition Visualization Technology (EVT), das vom Team unter
Leitung des Professors Robert Roselli Del Turco an der Universität in Pisa
entwickelt wurde. EVT ist eine einfache und gut modifizierbare Applikation für das
Web-Zugänglichmachen der digitalen, nach dem XML TEI-Standard gebildeten Editionen.
Sie bietet den Benutzern das komforte Forschungsmilieu, welches nicht nur das
bequeme Inhalts- und Registeraussuchen sondern auch Instrumente für die Kollation
der einzelnen Handschriften und Arbeit mit textkritischem Apparat bietet. Die Arbeit
mit EVT und die Funktionen dieses Instruments sind ausführlicher beschrieben auf
einer selbstständigen Seite.