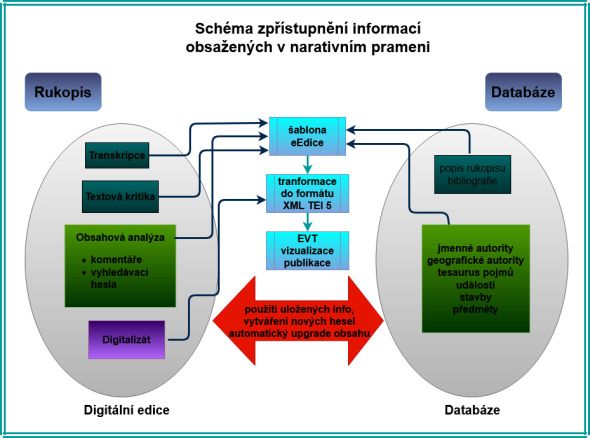
Digitální edice umožňuje na jednom místě zpřístupnit digitalizáty originálního
rukopisu spolu s vědeckou textově kritickou a komentovanou edicí textu a potřebnými
popisnými metadaty. Digitální edice LA je zpracována v mezinárodním standardu XML
TEI P5, který na jedné straně postihuje přesnou strukturální, formální i obsahovou
stránku pramene včetně evidence a správy verzí jednotlivých rukopisů a zároveň může
edici efektivně doplnit o nadstavbové, interpretační informace ze specializované
databáze, případně dalších zdrojů aniž by bylo nutné zasahovat do původního textu.
Proces přípravy edice a vyplňování databáze je přitom obousměrně propojen. Při
přípravě edice se vytváří nebo doplňují záznamy v databázi, a naopak informace
později doplněné do databáze z jiných zdrojů se zpětně promítnou do poznámkového
aparátu.
Při práci s texty postupujeme metodami obvyklými pro tvorbu edic bez ohledu na
formu jejího zpřístupnění. Na začátku tedy stojí zhodnocení kvality a dostupnosti
jednotlivých rukopisů a je zvolen hlavní rukopis. Poté provede kvalifikovaný
opisovač přepis textu a podle dochovanosti rukopisů se provádí kolace minimálně s
dalším jedním nebo více rukopisy. Pro vlastní ediční práci definujeme dvě formy
zpracování:
- Úplná textově kritická edice
- zpřístupňuje text na základě kolace všech rukopisů
- vytváří plný textově kritický aparát reflektující různé typy odlišností rukopisů
- zachycuje jevy, které mohou přispět k pochopení vzniku textu včetně autorských
škrtů
- Komentované edice se zjednodušeným textově kritickým
aparátem
- zpřístupňuje text na základě kolace s minimálně jedním z vedlejších rukopisů
- textově kritický aparát nereflektující typy zachycených variant
- nereflektuje ortografické varianty vyjma vlastních jmen a toponym
- nezachycuje autorské škrty
- vytváří komentáře pro snazší pochopení textu a rejstříky pro prohledání
První formu edice považujeme pro literae annuae za přínosnou jen tehdy, pokud
rukopisy vykazují podstatnějších rozdílů, nebo tam, kde se dochoval koncept zpráv s
opravami provedenými pisatelem nebo častěji korektorem, snad rektorem koleje.
Převažující formou edice LA proto bude komentovaná edice se zjednodušeným textově
kritickým aparátem, která je obohacena o interpretační prvky a propojení se
specializovanou databází, které usnadní další badatelskou práci.
Pravidla pro transkripci a ediční úpravy textů literae annuae vycházejí z
dosavadních statí věnujících se edicím raněnovověkých textů a zároveň reflektují
specifika jezuitských písemností i potřeby uživatelů edice.
Kromě standartního textově kritického aparátu, vytváříme pro digitální edici LA
také poměrně rozsáhlý systém obsahových komentářů, které ve formátu TEI zároveň
slouží jako základ rejstříků a dalších vyhledávacích služeb. Každý komentář je
propojen s příslušným záznamem v databázi, z něhož je automaticky generováno
odpovídající rejstříkové heslo. Vizualizační software pak umožňuje badateli přímý
přístup nejen k textově kritickým poznámkám, ale i k nadstavbovým rejstříkovým
informacím přímo z edice. Při interpretaci textů zaměřujeme pozornost zejména
na:
- Osoby
a to jak osoby v textech přímo jmenované, tak osoby identifikované na základě
zmíněných funkcí či rolí vztažených k času a místu popisovaném v prameni.
Například tam kde zprávy jmenují představitele církve nebo jezuitského řádu
vztahujeme obecná označení „decanus Telczensis“, „decanus Slavonicensis“,
„praepositus Neoreschensis" ke konkrétním lidem, kteří funkce v daném roce
vykonávali. Podobně když text zmiňuje aktivity zakladatelky nebo vrchnosti
dohledáváme k obecným termínům „fudatrix nostra“ nebo „illustrissimus hujatus
dominus“ jména příslušníků vládnoucího rodu.
- Korporace
zahrnující instituce, korporace a specifické organizace (např. studijní
nadace), které jsou v textech přímo jmenovány, označeny zástupnými pojmy nebo se
jich text dotýká. Například pro hudební seminář založený Františkou Slavatou
nacházíme v prameni označení „seminarium musorgorum“, „convictus musorgorum“,
„convictus Angelicus“ ale také prosté „seminarium nostrum“ či „convicus
nostrus“.
- Místa (Geografické termíny)
včetně identifikace lokality až na úroveň GPS souřadnic,
které umožňuje jejich zobrazení na mapě.
- Události
jde například o náboženské slavnosti (slavnostní mše,
procesí), divadelní představení, ale také stavební činnost (stavba sýpky,
založení rybníka), opravy nemovitostí (rekonstrukce střech, výmalby objektů,
výsadbu lesů a sadů), nákupy a prodeje statků, uzavírání smluv, řešení sporů,
pořizování a opravy movitých předmětů (knihy, nábytek, liturgické předměty a
oblečení, umělecké předměty). V případě, že se jedná o akci související s
movitými či nemovitými předměty odkazujeme i na příslušný předmět či stavbu.
- Stavby
za stavby považujeme všechny nemovité památky včetně drobné
sakrální architektury, hospodářských staveb a jejich součástí, které vznikaly
postupně i v rámci většího stavebního komplexu. Zachycujeme je jako místa děje
akcí, sídla korporací, objekty stavební činnosti či oběti katastrof. Do
kategorie „stavby“ zařazujeme i prvky kulturní krajiny a různé typy obdělávané
půdy (zahrady, pole, sady). Vzhledem k tomu, že řada staveb je zmiňována jako
„místo děje“, chápeme je také jako specifický typ lokality.
- Předměty
jako „předmět“ označujeme všechny movité věci od
liturgických předmětů, přes oblečení, nábytek až po kostelní mobiliář. Zařazujme
mezi ně také knihy, ač jejich evidence podléhá samostatným pravidlům. Většinu
zmiňovaných knih totiž nelze identifikovat s konkrétním dochovaným exemplářem, a
proto postupujeme podobně jako u jiných předmětů a v případě identifikovaných
knih pracujeme se standardním katalogizačním záznamem.
- Pojmy
podchycujeme všechny termíny vyskytující se v textech s
cílem vytvořit jejich rejstřík pro vyhledávání jak pomocí pojmů v jazyce
originálu textu, tak podle jejich českých ekvivalentů. Obvykle se jedná o
označení funkcí, předmětů, činností, církevních svátků a dalších skutečností,
jež se v textech vyskytují v řadě synonymických označení, která sdružujeme do
nejběžnějšího pojmu (např. pod termín „concionator“ jsou zahnuta synonyma
„encomiastes“, „pangeyrista“, „sacer orator“ apod.), a ten doplňujeme
vysvětlením jeho významu.
Formát XML TEI je v akademické komunitě obecně přijímaným standardem především pro
zpracování elektronických textů a digitálních dokumentů z oblasti humanitních věd.
Jeho základem je univerzální značkovací jazyk XML (eXtensible Markup Language) .
Formát TEI je vytvářen a spravován odborníky sdruženými v asociaci Text Encoding
Initiative . Struktura formátu TEI (poslední verze P5) definovaná v TEI Guidelines
se zaměřuje na popis obsahové struktury dokumentu a jeho metadat. Obsahuje komplexní
sadu elementů (značek) a příslušných atributů (vlastností) pro kódování širokého
spektra textů rozmanité povahy, stáří i formálního uspořádání (próza, poezie, drama,
slovníky, rukopisy, staré tisky …). Výsledný XML dokument může být za pomoci
kaskádových stylů (Cascading Style Sheets) a transformací (např. pomocí XSLT )
přizpůsoben různým výstupním formátům (web, tištěné medium, pdf, epub).
V kódování elektronické edice literae annuae využíváme kromě obecných značek
pro popis metadat (<teiHeader>) a formální struktury textu (odstavce, poznámky, bibliografické citace,
reference ) a zejména části TEI definic určených pro práci s rukopisnými texty a reprezentaci primárních pramenů. Pro propojení transkripce s
faksimilí používáme metodu paralelního přepisu (Parallel Transcription). Odkazovací systém kritického aparátu
je vytvářen paralelní segmentační metodou (Parallel Segmentation Method) s preferencí pozitivního
aparátu, tj. pro všechny položky kritického aparátu <app> uvádíme
elementy <lem> i <rdg>. Pro povahu projektu a práci s
komentáři jsou důležité elementy označující obsahové prvky dokumentu tzv. Named Entities. Vedle základních elementů <name>,
<date>, <place> používáme v projektu také značky pro označení
korporací <orgName>, událostí <event>, předmětů
<objectName> a pojmů <term>. Příslušné rejstříkové
seznamy jsou vytvářeny pomocí elementů <list> např.
<listPerson>, <listOrg>.
Pro každý rok existence LA se vytváří jeden samostatný XML soubor, který obsahuje i
kódování variantních rukopisů s užitím elementu <listWit> a
odkazovacího atributu @wit. Příklady kódování pro pilotní roky edice LA 1702
(úplná textově kritická edice) a 1729 (kometovaná edice se zjednodušeným textově
kritickým aparátem) a podrobný přehled typů textových variant, sémantických
komentářů a rejstříkových hesel a jejich reprezentace elementy TEI jsou k dispozici
ke stažení jako přílohy č. 3, 6, 8, 9, 10 certifikované metodiky.
Protože přímé kódování textů v XML editoru se jeví pro většinu spolupracovníků jako
obtížné, využíváme pro editorskou práci nástroj E-edice, vyvinutý pracovníky
Oddělení vývoje jazyka Ústavu pro jazyk český a popsaný v "Metodice pro přípravu a
zpracování elektronických edic starších českých textů". E-edice je naistalována
jako šablona (eEdice.dotx) a doplněk textového editoru MS Word a slouží k označování
relevantních částí pramenného textu a vytváření textově kritických a obsahových
komentářů. V šabloně definované odstavcové a znakové styly jsou v dalších krocích
automaticky převáděny na odpovídající elementy formátu TEI P5. Šablona obsahuje také
úvodní tabulku pro zápis metadat. Pro naše potřeby byla původní verze šablony
přizpůsobena práci s variantními rukopisy a doprogramováno propojení s databází, tak
aby bylo možné zároveň se zpracovávání textu edice propojovat a aktualizovat záznamy
v databázi.
Po dokončení jsou wordovské dokumenty ve spolupráci z kolegy z ÚJČ řadou XSLT
transformací převedeny do XML souborů, které prochází ještě finální revizí v editoru
Oxygen. Přehled použitých stylů a jejich převod do TEI a příklady
editorské práce v šabloně E-edice pro pilotní roky 1702 (úplná textově kritická
edice) a 1729 (kometovaná edice se zjednodušeným textově kritickým aparátem) jsou k
dispozici ke stažení jako přílohy č. 1, 2, 5 certifikované metodiky.
Jako databázi pro ukládání dat využívaných E-edicí, resp. excerpovaných z
editovaných textů využíváme Bio-bibliografickou databázi řeholníků v českých zemích
v raném novověku (BBDR). Databáze vznikla v roce 2010 a byla koncipována jako
prostor ke shromažďování informací o životě řeholních společenství. Jejím základem
je modifikovaný knihovní systém Clavius respektující mezinárodní knihovnické
standardy MARC21 a UNIMARC. Nejprve byly akcentovány biografické informace a jejich
pramenné zdroje. Posléze se databáze se rozvinula do dvou hlavních modulů: databáze
hlavních autorit (= databáze řeholníků 17. a 18. století z českých zemí, tj.
biografická) a katalog rukopisů (= databáze narativních historiografických pramenů
řeholní provenience 17. a 18. století, tj. bibliografická). Dalšími bibliografickými
moduly jsou katalog starých tisků a katalog knih, které však mají pouze podpůrnou
funkci.
Kromě všech výše zmíněných modulů využívá digitální edice také moduly geografických
autorit a korporací. Nově byl přizpůsoben modul věcných autorit, tak, aby bylo možné
v databázi evidovat jednak pojmy a funkce související s životem jezuitské komunity
(včetně např. evidence církevních svátků) a jednak informace stavbách a dalším
movitém i nemovitém majetku zmiňovaném ve výročních zprávách. Všechny záznamy v
databázi jsou opatřeny propracovaným systémem aliasů, tak aby bylo usnadněno
vyhledávání nejen podle synonymických označení v latině, ale i podle jejich českých
překladů a nejrůznějších variant místních a osobních jmen. Například:
- Telč - Telcz - Teltsch
- Ignatius de Loyola - divus Patriarcha Noster Ignatius - Sanctus Patriarcha
Noster - Ínigo López de Loyola - Ignác z Loyoly
- Daemon - Diabolus - Ďábel - Malignus spiritus - Spiritus malignus
- seminarium musorgorum - seminář svatých andělů - hudební seminář - convictus musorgorum - convictus Angelicus
V případech, kde to umožňuje platná legislativa, jsou součástí elektronické edice
litearae annuae jsou také elektronické kopie jednotlivých dochovaných
rukopisů. Použitý vizualizační systém EVT umožňuje propojení
textu s digitálním obrazem originálu buď na úrovni stránek (pomocí elementu
<pb>) nebo řádků (<lb>). Digitalizáty získané nebo
pořízené v paměťových institucích je však pro účely webové publikace nutné formálně
upravit a sjednotit. Pro tyto účely využíváme opensourcový program Scan Tailor,
který slouží k dávkovému zpracování obrazových dat. Program umožňuje provádět
následující operace:
- úprava orientace stran (otočením o 90, popř. 180 stupňů)
- rozdělení folií na jednotlivé strany (dvoustrana se rozdělí na samostatné
strany)
- detekce a oříznutí prázdných okrajů kolem textu
- vyrovnání řádků pomocí jemného pootočení obrázku
- nastavení výstupních parametrů obrázků (formát, velikost, rozlišení
DPI)
Výhodou zvoleného programu je, že úpravy obrazu umí sám detekovat a
aplikovat na všechny soubory ve složce. Pokud některý soubor obsahuje nestandardní
prvky, je možné jednotlivé kroky upravit manuálně.
Pro publikaci edice literae annuae používáme open source vizualizační nástroj
Edition Visualization Technology (EVT) vyvíjený na Universitě v Pise týmem vedeným
profesorem Robertem Rossellim Del Turco. EVT je jednoduchá a dobře modifikovatelná
aplikace pro webové zpřístupnění digitálních edic vytvořených podle standartu XML
TEI, která uživatelům nabízí komfortní badatelské prostředí umožňující nejen
pohodlné obsahové a rejstříkové vyhledávání, ale i nástroje pro kolaci jednotlivých
rukopisů a práci s textově kritickým aparátem. Práce s EVT a jeho funkce jsou
podrobněji popsány na samostatné stránce.